 Google met à disposition son propre outil OCR pour"Optical Character Recognition". Il s'agit d'une technologie capable d'extraire du texte d'un document scanné de type pdf ou image. Nous verrons comment utiliser ce nouveau service made in google.
Google met à disposition son propre outil OCR pour"Optical Character Recognition". Il s'agit d'une technologie capable d'extraire du texte d'un document scanné de type pdf ou image. Nous verrons comment utiliser ce nouveau service made in google.
L'idée principale d'un tel outil est de pouvoir rendre exploitable le texte d'un fichier scanné, d'une image ou d'un pdf qui a perdu son vectoriel.
Nous avions discuté il y a quelque temps de services en ligne qui proposent la reconnaissance du texte par détection OCR. A cette époque, cet outil puissant de reconnaissance était considéré comme une véritable prouesse technologique mise à la portée de tous. Mais à quel prix?
Ces services proposé gratuitement en ligne étaient intéressants à utiliser mais aussi très contraignant à cause des limitations faites sur le nombre de mots ou bien encore sur le poids des fichiers à traiter. Dommages....
Il n'y a donc plus de limitations avec Google puisque ce dernier rend son service de reconnaissance du texte accessible à tous et ce de manière illimité.
Procédure
- D'abord, Ouvrir son compte Google drive
- Ensuite, se rendre dans les paramètres:

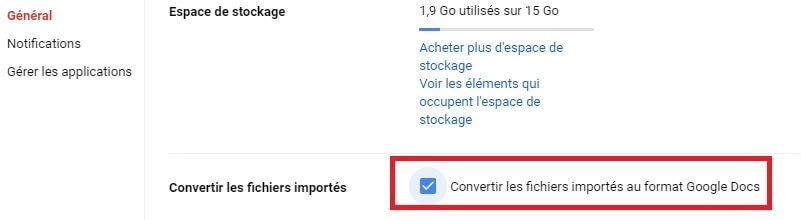
- Cocher l'option convertir les fichiers importés au format Google Docs:
- Importer l'image ou le pdf à convertir dans votre drive (déposer glisser)
- Enfin, ouvrir votre image ou document pdf avec Google Docs:
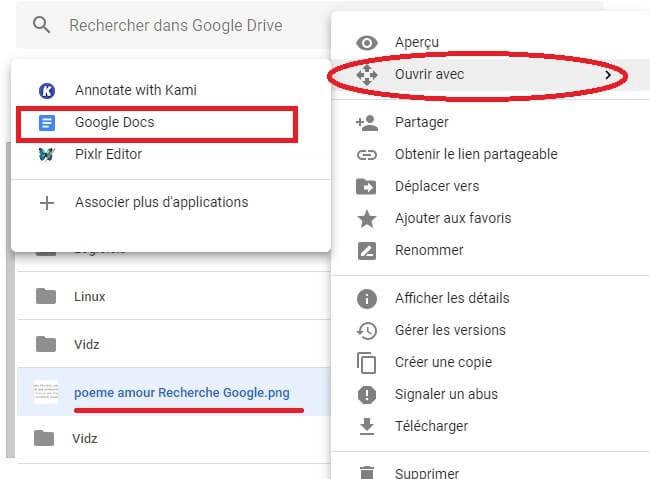
Faire un clic droit sur votre fichier / Ouvrir avec / Google Docs
- Votre image s'ouvrira sur Google Docs suivi de son texte extrait de l'image, appréciez:

Enjoy!!
